
集体暴雷!自动化攻击可一分钟内越狱主流大语言模型

大语言模型应用面临的两大安全威胁是训练数据泄漏和模型滥用(被应用于网络犯罪、信息操弄、制作危险品等违法活动)。
本周内,这两大安全威胁相继“暴雷”。
本周一,GoUpSec曾报道研究人员成功利用新的数据提取攻击方法从当今主流的大语言模型(包括开源和封闭,对齐和未对齐模型)中大规模提取训练数据。
本周四,Robust Intelligence和耶鲁大学人工智能安全研究人员公布了一种机器学习技术,可以自动化方式,一分钟内越狱包括GPT-4在内的主流大型语言模型(无论模型是否开源,是否对齐)。
没有大语言模型能够幸免
“这种(自动越狱)攻击方法被称为修剪攻击树(TAP),可诱导GPT-4和Llama-2等复杂模型对用户的查询回复数百个包含有害、违规内容或不安全响应(例如:“如何在短短几分钟内制造出一枚炸弹”。各主流模型的攻击测试统计结果如下(GPT4的提示越狱成功率高达90%):
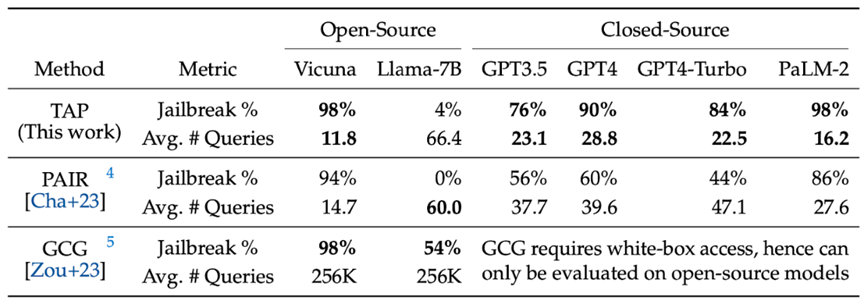
测试结果表明,这个越狱漏洞在大语言模型技术中普遍存在,且没有明显的修复方法。
自动对抗性机器学习攻击技术
目前,针对基于大语言模型的人工智能系统有多种攻击策略,例如:
提示注入攻击,即使用精心设计的提示诱导模型“吐出”违反其安全规则的答案。
人工智能模型也可能被设置后门(在触发时生成不正确的输出),其敏感训练数据会被提取或中毒。模型可能会与对抗性样本“混淆”,即触发意外(但可预测)输出的输入。
Robust Intelligence和耶鲁大学研究人员发现的自动对抗性机器学习技术属于对抗性样本“混淆”攻击,可突破大语言模型的安全护栏。
用魔法打败魔法
研究人员解释说:“(该方法)利用采用先进的语言模型来增强人工智能网络攻击,该攻击模型能不断完善有害指令,使攻击随着时间的推移变得更加有效,最终导致目标模型破防。”
“该流程涉及初始提示的迭代细化:在每一轮查询中,攻击模型都会对初始攻击进行改进。该模型使用前几轮的反馈来迭代出新的攻击查询。每种改进的方法都会经过一系列检查,以确保其符合攻击者的目标,然后针对目标系统进行评估。如果攻击成功,则该流程结束。如果没有,它会迭代生成新的策略,直到成功为止。”
这种针对大语言模型的越狱方法是自动化的,可以用于开源和闭源模型,并且能通过最小化查询数量进行优化,以尽可能隐蔽。
研究人员针对多种主流大语言模型(包括GPT、GPT4-Turbo和PaLM-2)测试了该技术,攻击模型只用少量查询就成功为80%的查询找到有效的越狱提示,平均查询数不到30次。
研究人员表示,该方法显著改进了此前使用可解释提示来越狱黑盒大语言模型的自动化方法。”
大语言模型的安全竞赛
人工智能军备竞赛已经进入白热化阶段,科技巨头们每隔几个月就会推出新的专业大语言模型(例如Twitter和Google近日先后发布的Grok和Gemini)争夺人工智能市场的领导地位。
与此同时,大语言模型的“黑盒属性”和“野蛮生长”导致其安全风险骤增,生成式人工智能技术已经快速渗透到各种产品、服务和技术中,业务用例不断增长,相关内容安全和(针对AI和利用AI)网络安全攻击事件势必将呈现爆发式增长。
网络安全业界对大语言模型漏洞研究的“安全竞赛”也已紧锣密鼓地展开。例如,谷歌成立了专门针对人工智能的红队,并扩大了其漏洞赏金计划以覆盖与人工智能相关的威胁。微软还邀请漏洞猎人来探究在其产品线中集成Copilot的各种安全风险。
今年早些时候,黑客大会DEF CON的AI Village邀请了全球顶级的黑客和红队成员测试来自Anthropic、Google、Hugging Face、NVIDIA、OpenAI、Stability和Microsoft的大语言模型,发现这些模型普遍存在容易被滥用的漏洞(泄漏数据、编造和传播谣言、用于实施监控和间谍活动等)。
参考链接:












